
생활 코딩 PHP 07 - 정규 표현식
01 Dec 2019 | 생활코딩 PHP1. 정규표현식
정규 표현식(正規表現式,Regular Expression)은 문자열을 처리하는 방법 중의 하나로 특정한 조건의 문자를 ‘검색’하거나 ‘치환’하는 과정을 매우 간편하게 처리 할 수 있도록 하는 수단
1.1 GET STARTED - 구분자
- 정규표현식인 부분과 아닌 부분을 구분하기 위해 사용하며 특수부호를 씀.
- /foo bar/im 에서 im을
pattern modifier이라고 함 (패턴을 동작하는 방법을 수정)i: 대소문자 구분하지 않도록 함m: multiline 각각의 행마다 조건을 적용시킬 때 사용
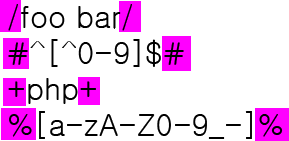

예시)
preg_match: 검새을 수행하고 일치하는 내용을 반환함.- 검색이 된다면 1을 반환. 그렇지 않을 경우 0을 반환(문법적인 오류는 false 반환)
<?php
if (preg_match("/php/i", "PHP is the web scripting language of choice.")) {
echo "A match was found.";
} else {
echo "A match was not found.";
}
?>
1.2 검색
\b: word boundary; 단어의 경계를 의미함. \b로 감싸진 web은 web이라는 독립된 단어를 의미함. website는 web과 site가 결합된 단어이기 때문에 이 조건에 해당하지 않음.
<?php
if (preg_match("/\bweb\b/i", "PHP is the web scripting language of choice.")) {
echo "A match was found.";
} else {
echo "A match was not found.";
}
if (preg_match("/\bweb\b/i", "PHP is the website scripting language of choice.")) {
echo "A match was found.";
} else {
echo "A match was not found.";
}
?>
.: any character
<?php
$subject = 'coding everybody http://opentutorials.org egoing@egoing.com 010-0000-0000';
preg_match('/coding/', $subject, $match);
#preg_match가 검색결과를 3번째 인자(변수; $match)에 저장시킴
print_r($match);
?>
<?php
$subject = 'coding everybody http://opentutorials.org egoing@egoing.com 010-0000-0000';
preg_match('/c...../', $subject, $match);
print_r($match);
?>
- 슬러쉬(
/)를 써야하는 경우 - escaping & 다른 구분자 사용
<?php #도메인 추출 - 슬러쉬인 /을 넣어야할 경우 \ 사용(escaping)
$subject = 'coding everybody http://opentutorials.org egoing@egoing.com 010-0000-0000';
preg_match('/http:\/\//', $subject, $match);
print_r($match);
?>
<?php #도메인 추출 - 슬러쉬인 /을 넣어야할 경우 다른 구분자 사용
$subject = 'coding everybody http://opentutorials.org egoing@egoing.com 010-0000-0000';
preg_match('~http://\w+~', $subject, $match); #w: 문자를 의미 +: 하나이상이라는 수량자
print_r($match);
?>
<?php
$subject = 'coding everybody http://opentutorials.org egoing@egoing.com 010-0000-0000';
preg_match('~http://\w+.~', $subject, $match); #. : any character
print_r($match);
?>
<?php
$subject = 'coding everybody http://opentutorials.org egoing@egoing.com 010-0000-0000';
preg_match('~http://\w+\.\w+~', $subject, $match); # any character로 사용되지 않도록 escaping 처리
print_r($match);
?>
- 캡쳐링(역참조) : ()로 정규표현식의 패턴을 묶으면 독립된 데이터로 추출할 수 있음
<?php
$subject = 'coding everybody http://opentutorials.org egoing@egoing.com 010-0000-0000';
preg_match('~(http://\w+\.\w+)\s(\w+@\w+\.\w+)~', $subject, $match); #\s 공백을 의미
print_r($match);
# $match[0] 에는 전체 데이터가 저장되어 있음.
echo $match[1];
echo $match[2];
?>
- 응용 1)
<?php
preg_match('@^(?:http://)?([^/]+)@i',
#^ => 경계를 의미함. http://로 시작하는 것을 검사
#?: => matches 라는 배열안에 http:// 가 담기지 않음.
#? => 수량자: 0~1 http:// 가 없거나 있거나. 1개만 등장
#대괄호 안의 ^ => not(부정)을 의미.
#[^/] => /가 아닌 전체문자를 의미 (www.php.net)
"http://www.php.net/index.html", $matches);
print_r($matches);
$host = $matches[1];
// get last two segments of host name
# / => 구분자
# [^.] => .이 아닌 문자
# + => 수량자(.이 아닌 문자가 1개 이상)
# \. => .을 문자로 처리
# $ => 문자열의 끝에 해당하는 경계
preg_match('/[^.]+\.[^.]+$/', $host, $matches);
print_r($matches);
echo "domain name is: {$matches[0]}\n";
?>
- 응용 2) - Back Reference
<?php
$str = 'foobar: 2008';
preg_match('/(?P<name>\w+): (?P<digit>\d+)/', $str, $matches);
/* This also works in PHP 5.2.2 (PCRE 7.0) and later, however
* the above form is recommended for backwards compatibility */
// preg_match('/(?<name>\w+): (?<digit>\d+)/', $str, $matches);
print_r($matches);
?>
Comments