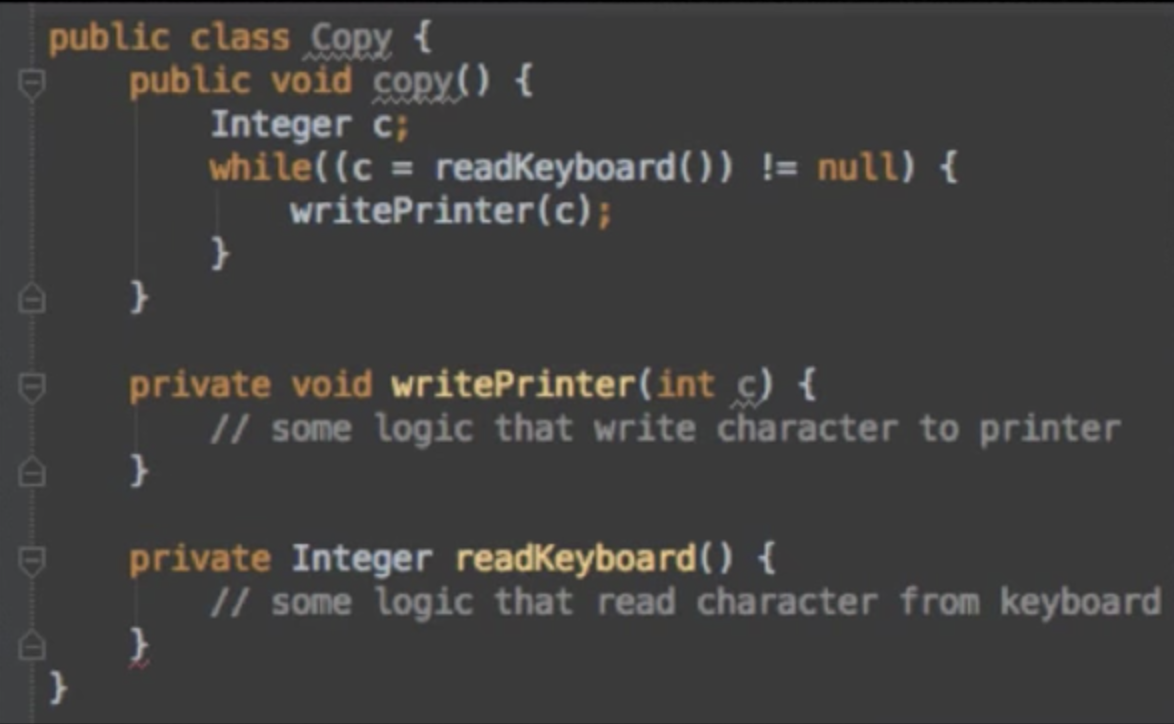
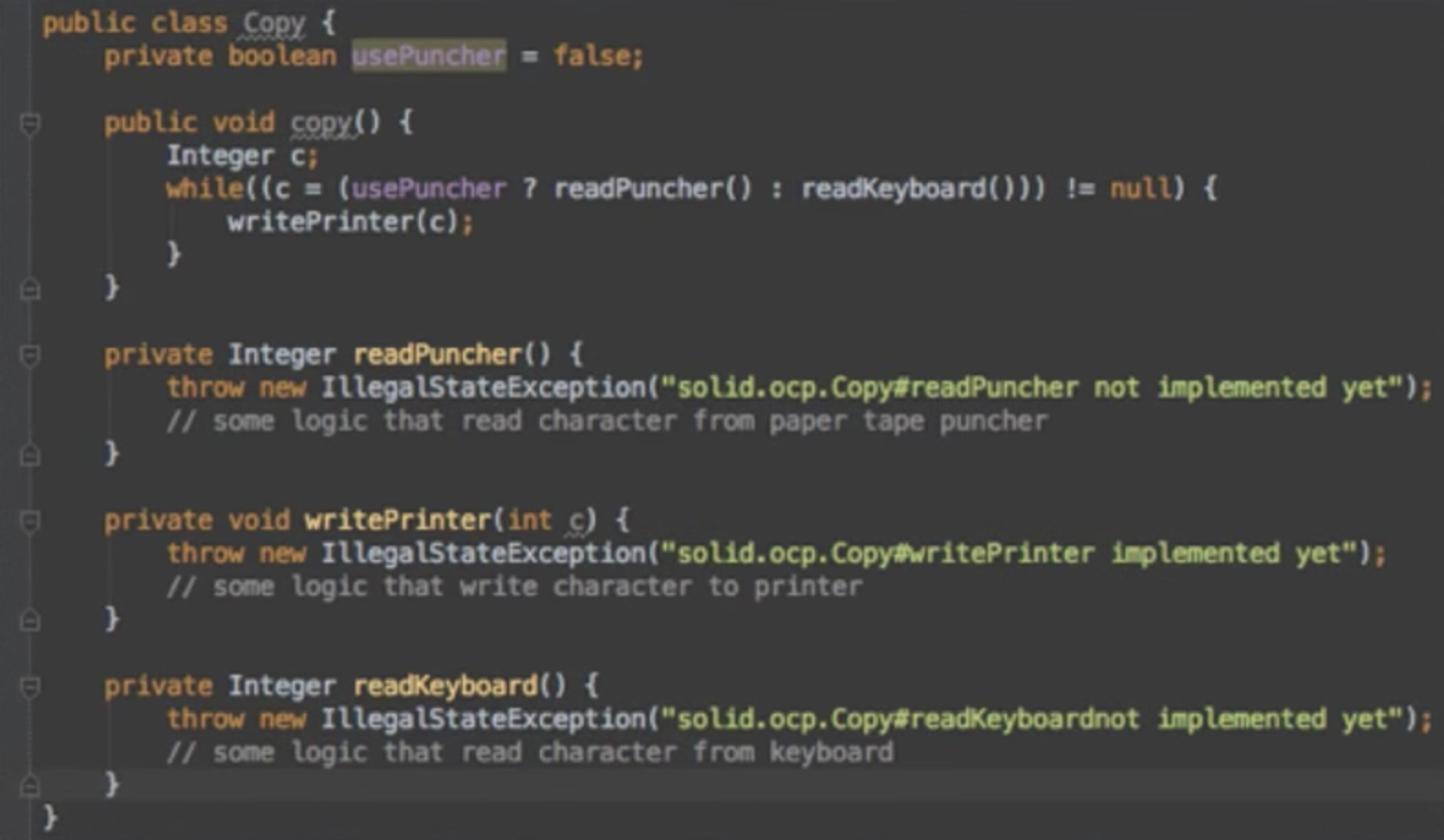
Clean code - SOLID 05 - Dependency Inversion Principle (DIP)
03 Feb 2020 | clean coders clean architecture architecture OOP SOLID백명석님의 클린코드 강의 를 듣고 정리한 포스팅 입니다.
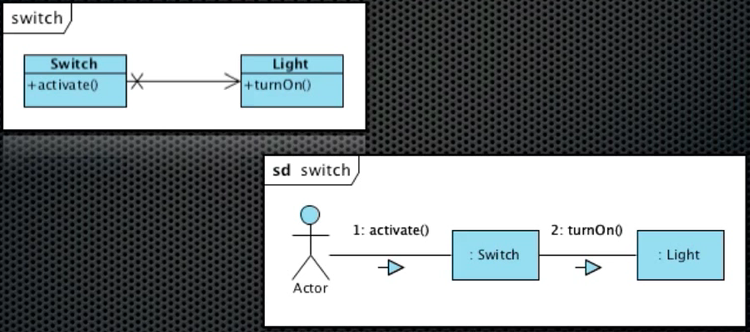
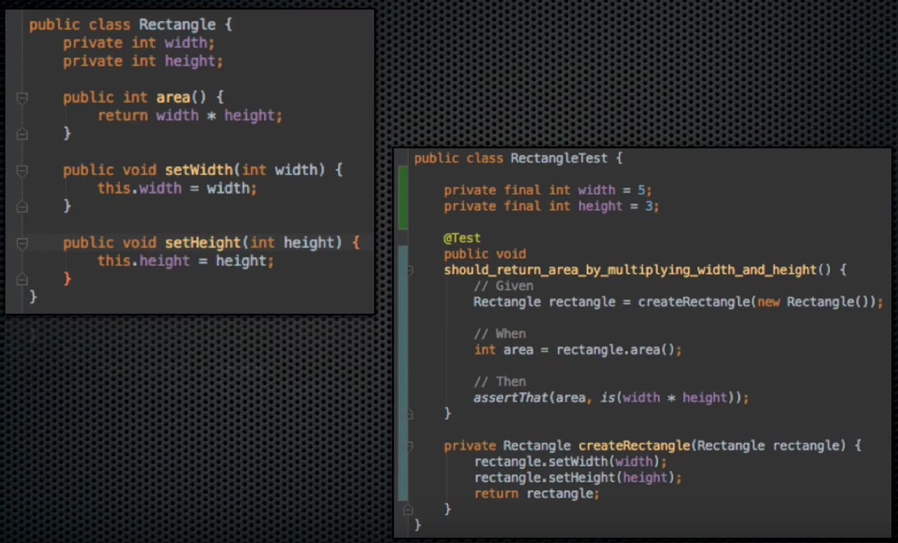
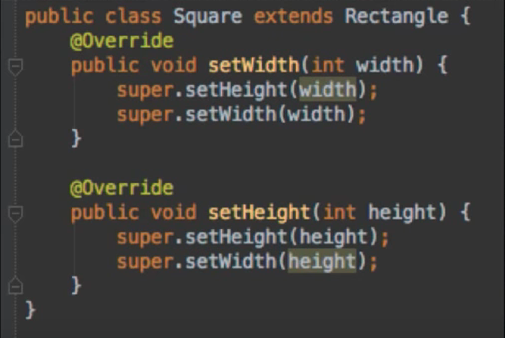
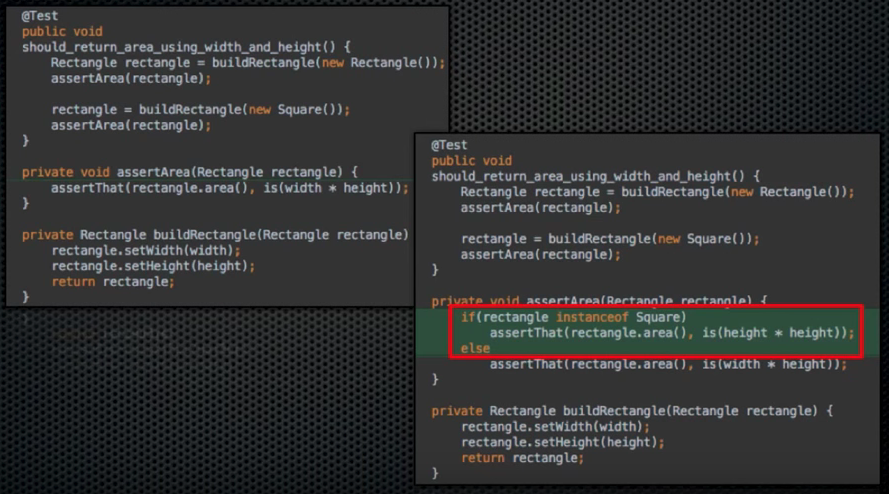
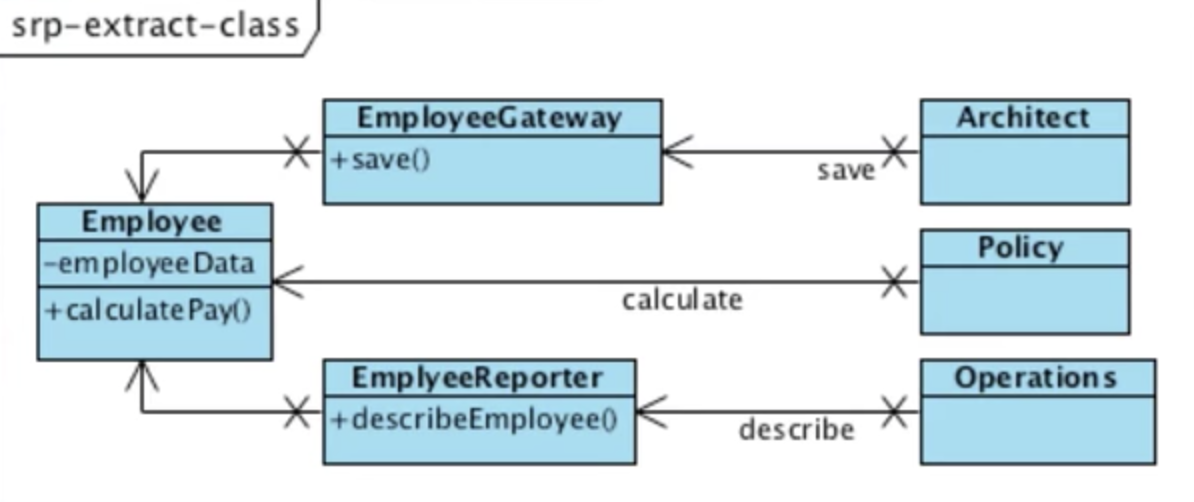
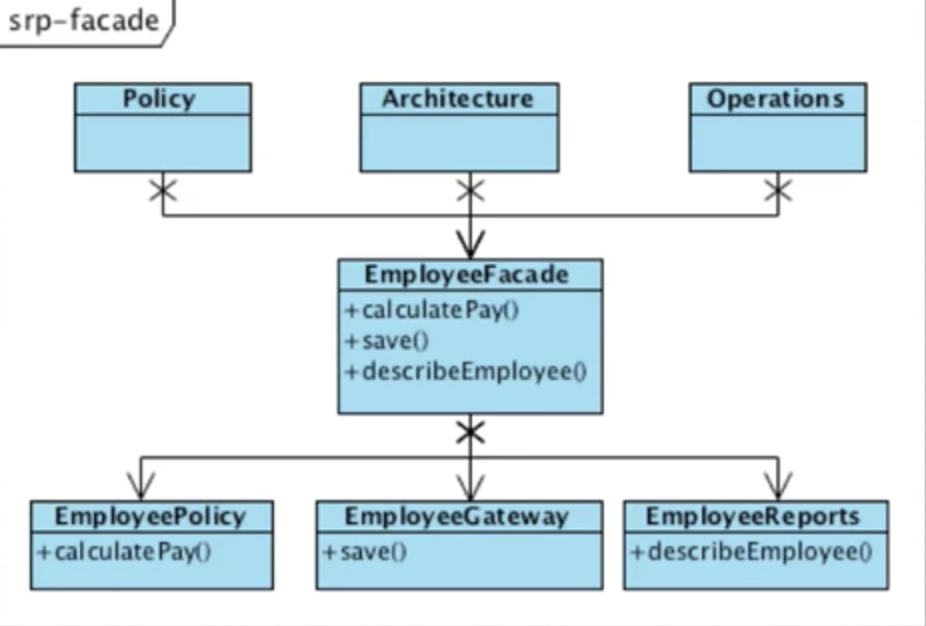
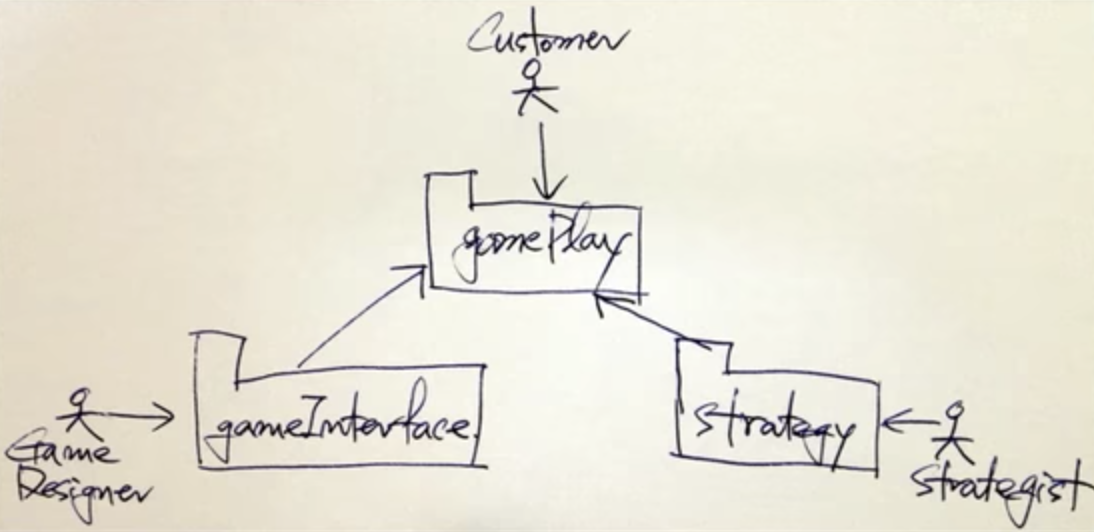
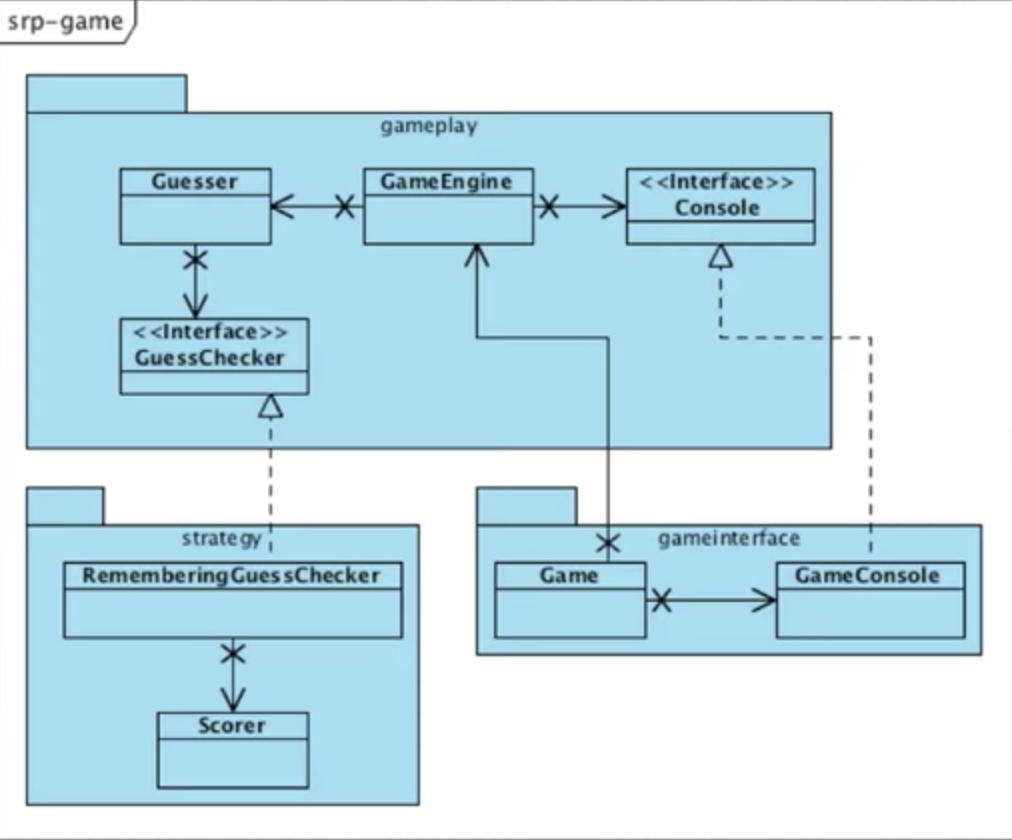
1. Dependency Inversion Principle
상위 레벨의 정책은 하위 레벨의 정책에 의존하면 안됨. 둘은 Abstract Interface에 의존해야 한다.
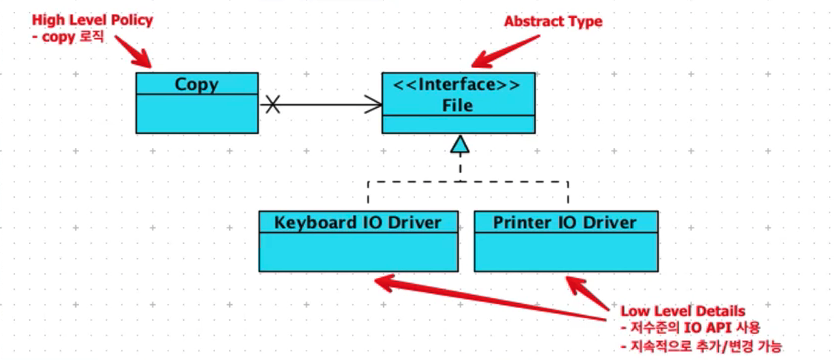
2. 객체지향의 핵심
Inheritance, Encapsulation, Polymorphism는 객체지향의 핵심이 아니라 객체지향의 매커니즘임. 객체지향의 핵심은 IoC를 통해 상위 레벨의 모듈을 하위 레벨의 모듈로 부터 보호하는 것
- 제어의 흐름을 역전시켜 (IoC), 상위레벨의 로직이 하위 레벨의 로직에 의해 변경이 되지 않도록 하는 것 (하위 레벨의 변경은 빈번하게 일어 날 수 있음)
- OCP를 통해 새로운 요구 사항을 반영할 수 있음. (SOLID의 개념은 상호 보완 적임. DIP는 OCP와 밀접한 연관이 있음)
- 객체지향 설계의 핵심은 의존성 관리(depedency management)
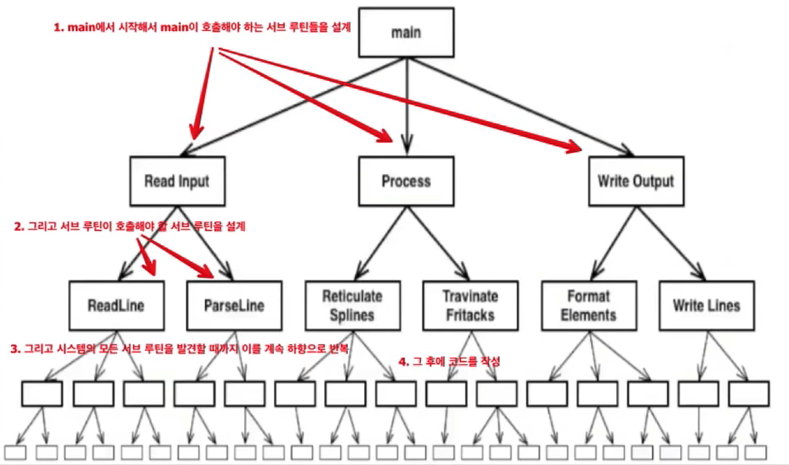
3. Structured Design
Top-down 방법론
- 구조적 설계를 하게 되면 Top-down 방법으로 설계하게 됨.
- 소스코드 의존성 방향 === 런타임 의존성 방향
- 소스코드 의존성 방향이 역전되어야함!
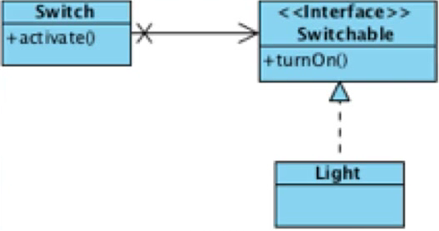
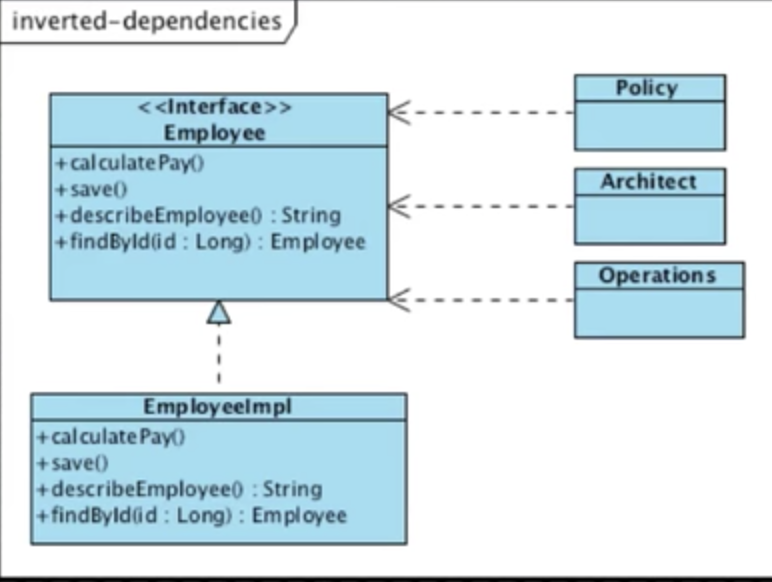
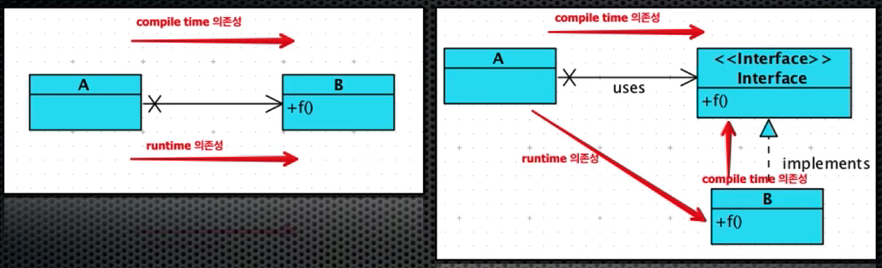
4. Dependency Inversion
A와 B 사이에 polymorphic interface를 삽입
A는 인터페이스를 사용하며, B는 인터페이스를 구현함. 이를 통해 A(상위 레벨 로직)는 인터페이스가 변경되지 않는 이상, B(구체적인 로직. 하위 레벨 로직)의 변경에 자유로워 짐.
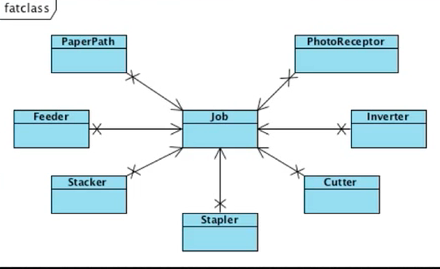
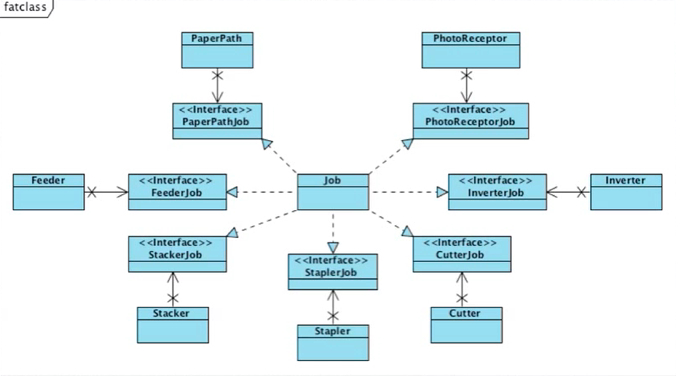
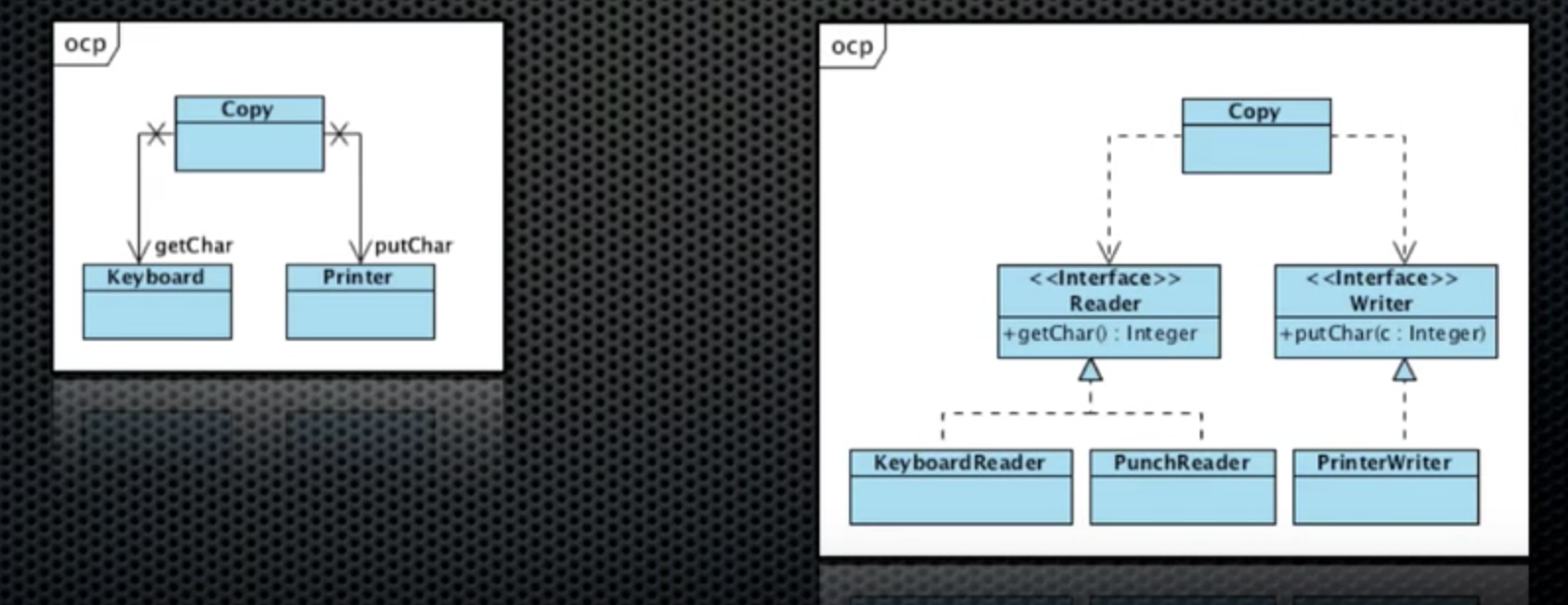
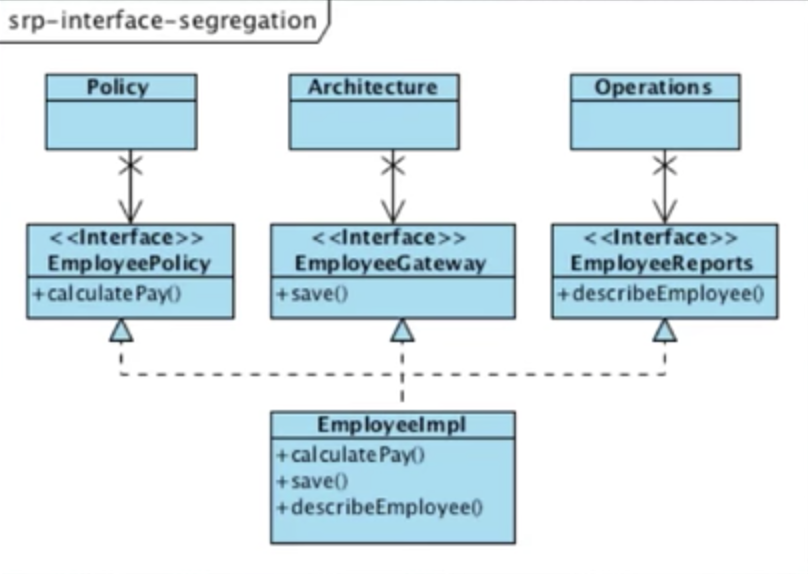
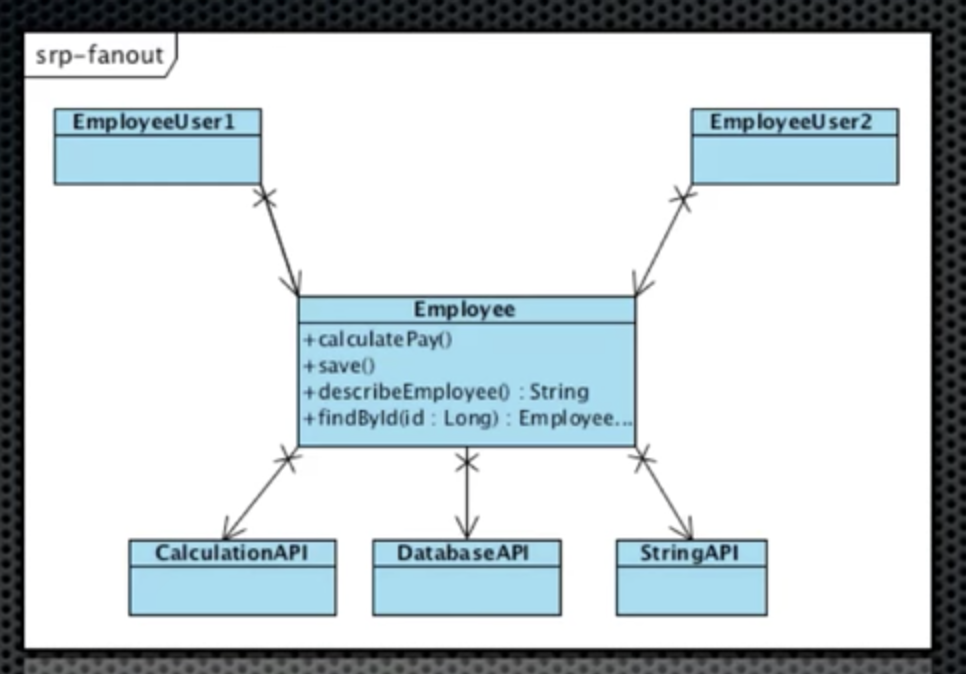
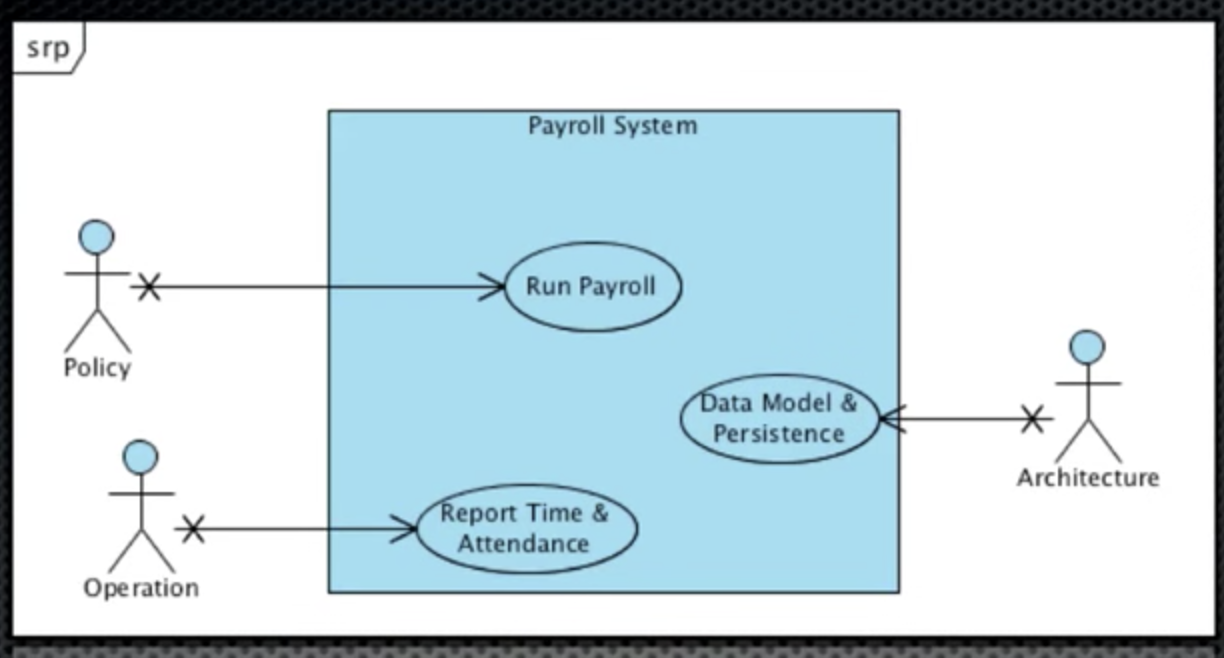
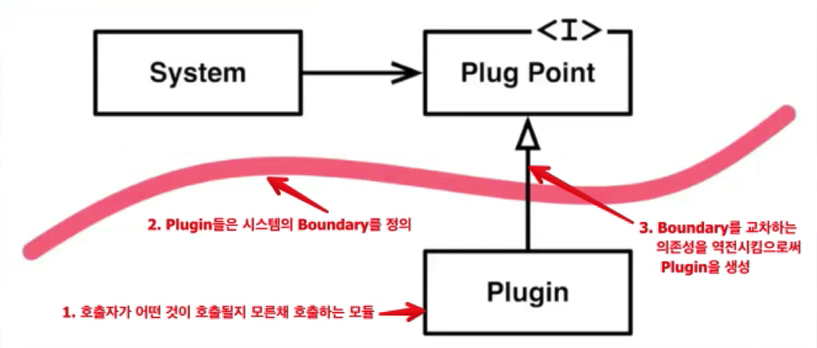
5. Plugins
어떤 시스템이 있을 때, 시스템을 사용하는 변경가능한 부분을 플러그인이라고 함. 시스템이라고 하는 호출자는 어떤 플러그인이 호출될줄 모름. 다만 플러그 포인트라는 인터페이스를 준수하는 하위레벨이 호출됨.
- Boundary를 Plugin Interface로 다룸
- 의존성 역전이 SW 모듈간의 경계를 만드는 수단
- 아래 예시에서 위의 부분은 Application layer, 아랫 부분은 web layer/database layer등이 될 수 있음
- Boundary를 교차하는 의존성의 방향은 반드시 하나여야만 함.
Boundary는 우리가 플러그인을 만드는 방법과 같다. 경계를 만들고자 할 때마다 어떤 의존성을 역전시킬 것인지를 고심해야함.
- 경계를 교차하는 의존성의 방향이 같도록
- 경계로 시스템을 나누고 경계를 교차하는 의존성을 역전
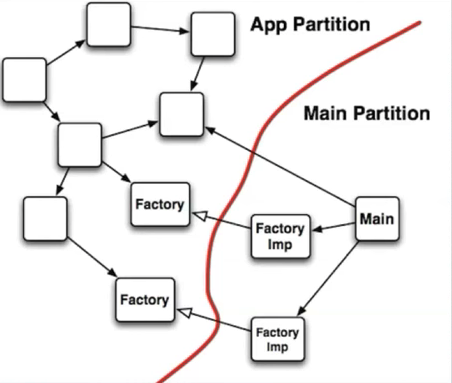
플러그인 아키텍처를 설계하면 아래와 같은 구성이 됨(메인은 시스템 어플리케이션에 플러그인 된다)
- App Partition: 일반적인 자바 코드가 존재하는 곳
- Main Partition: 하위 레벨
6. Architectural Implications
DIP가 아키텍처 측면에서 의미하는 바는 아래와 같음. Use Case, DB, Web 등을 분리하는 boundary 간의 의존성을 역전시키기 위해 DIP가 사용됨
- 젤 왼쪽에 controller가 있음. 사용자 요청을 받으면 컨트롤러가 해석 (ex. 웹: HTTP 요청 또는 쿠키 정보 해석)한 후 필요한 정보를 뽑아 냄. 이후 Request Model을 create 함
- Request Model은 인터페이스임. 컨트롤러는 실제로는 Request Model을 create하는 것이 아니라 Request Model를 구현하는 클래스 중 하나의 개념
- Boundary(그림에서 Request Model 2칸 아래에 위치)를 통해 Application에 request를 던짐.
- Boundary를 구현하고있는 Interactor (Use Case를 담당하는 객체)가 요청을 받음.
- Repository를 통해 데이터베이스에서 어떠한 entity들을 읽음.
- entity들에게 “ㅇㅇ해라” 라고 일을 시킴(entity들의 상태가 변경됨)
- Repository에게 entity의 변경된 상태를 저장해라고 명령을 내림
- Response Model(인터페이스)을 만든 후, Response Model을 구현하고 있는 data structure에 화면에 뿌릴 때 필요한 부분을 다 채워서 넘김
- 컨트롤러가 받아서 본인이 Presenter를 호출해도 되며, 혹은 컨트롤러가 Boundary를 통해 use case를 호출할 때, Presenter에 대한 레퍼런스를 넘겨도 됨.
- Response Model을 Interactor가 호출한다는 것은 화면에 그림을 그리는 친구(Web의 경우 HTML)를 호출한다는 것을 의미
- Use Case는 HTML을 호출할 수 없음. 따라서 Presenter(화면에 뿌릴 정보를 만드는 역할)를 통해 화면에 뿌림
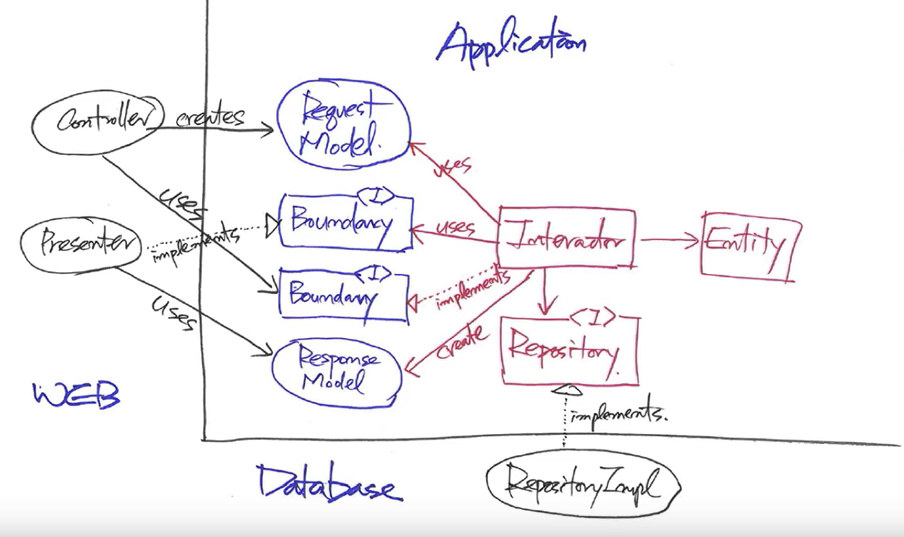
소스 코드 의존성의 방향을 살펴보면 어플리케이션에서 WEB 이나 Database로 가는 경우는 없음. 모두 어플리케이션을 향하고 있음. 이것이 바로 DIP가 아키텍쳐에서 갖는 의미라고 할 수 있음.
7. A Reusable Framework
객체지향이 과거 지향했던 재사용성이 통하지 않는 이유?
2인이 1년간 개발한 10만 라인 중 88%의 코드가 reusable framework에 있었음. 고객은 만족했고 추후 3개의 어플리케이션을 더 계약하였음. 하지만 resuable framework가 다른 3개의 어플리케이션에 적합하지 않다는 것을 알게되었음.
그래서 재사용 못하고 바닥부터 다시 만듦. 고객에게는 7만 7천 라인의 코드가 reusable하지 않다고 진실을 말할 수 밖에 없었음.하지만 시간과 비용을 고려했을 때 reusable한 코드가 있어야 만 했다.
그래서 고객은 첫 어플리케이션에서 만든 reusable framework를 버리고 바닥부터 만드는 대신 다시 한번 재사용 가능성을 검토하길 원했다. 그래서 다시 검토하였고 이번엔 3개의 어플리케이션을 병렬로 개발하였다. 그 결과 2 man years 동안 다시 7만 7천 라인의 reusable framework를 만들었다.
3개의 어플리케이션에서 이 framework는 재사용되었다. 이후에는 계속해서 시간과 비용을 줄이면서 개발 할 수 있었다. reusable framework를 만드는 일은 매우 어렵다. 2개 이상의 어플리케이션을 병렬로 개발하지 않는다면 거의 실패할 것이다.
재사용 가능한 코드
- 만드는 노력: 3배
- 유지하는 노력: 10배
8. The Inversion
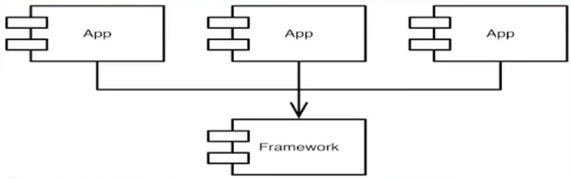
어플리케이션이 프레임워크에 의존성을 가짐. 하지만 프레임워크는 어플리케이션에 의존성을 갖지 않음.
- 프레임워크의 High Level Policy는 어플리케이션의 Low Level Detail에 대한 의존성이 없음.
- 일반적인 Structured Design(High level Module이 Low Level Module에 의존성을 갖는)과는 반대
9. The Furnace Example
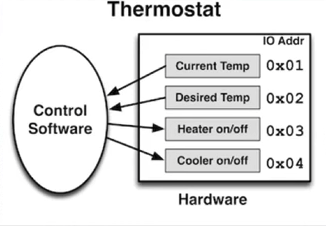
벽에 있는 Thermostat(온도조절장치)을 제어하는 소프트웨어를 개발해야한다고 가정
2개의 input과 2개의 output을 갖는 장치
- 2개의 input: 현재 온도/희망 온도를 반환
- 2개의 output: heater/cooler를 켜고/끄기 위한 boolean 값을 수신
특정 메모리주소를 바탕으로 온도 조절을 할 경우, 우측예시처럼 무한루프를 돌면서 조절이 될 것임. 이건 DIP에 위반됨.
- regulate가 알고리즘이며, low level detail에 의존
- High level control algorithm은 다른 디바이스와는 사용될 수 없음
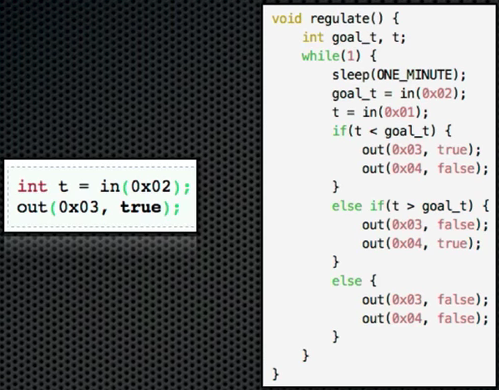
DIP에 순응하도록 변경
- HVAC이라는 인터페이스를 생성
- 컨트롤러(Thermostat Controller)가 하드웨어 컨트롤러(Hardware Controller)에 직접적인 의존성을 갖지 않게 됨
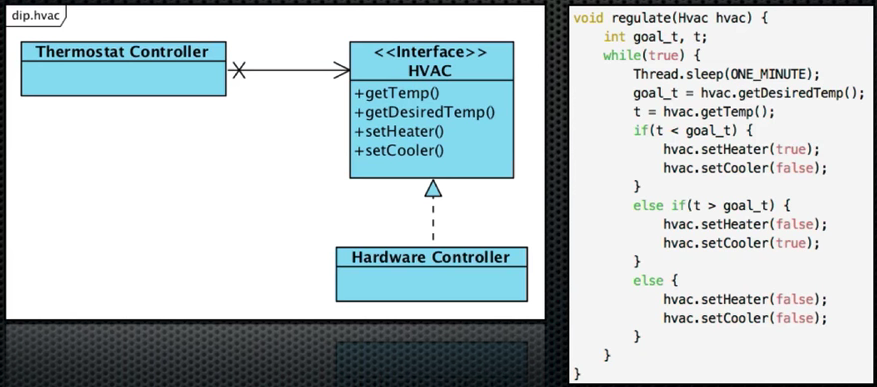
10. OCP vs DIP
위의 완성된 구조는 OCP때와 다를바가 없어보임. OCP와 DIP는 얼핏 비슷해보이나 목적/의도가 다름. 현재 하드웨어 컨트롤러에는 히터와 쿨러가 들어가 있음. 이때 히터와 쿨러 외에도 다른 것들이 들어갈 수 도 있음 (OCP 확장의 개념).
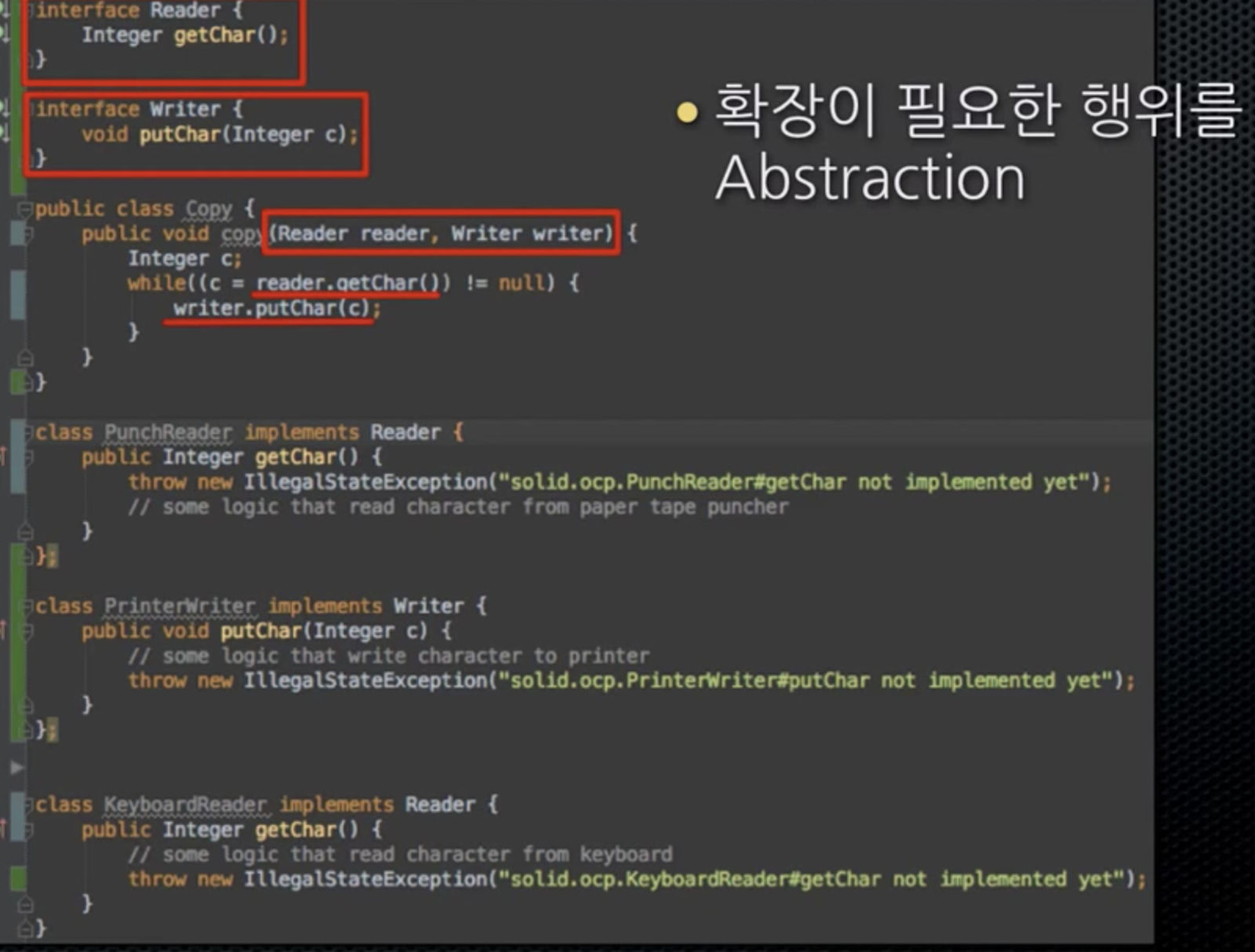
- OCP에서는 확장에 필요한 행위(영역)를 Abstraction함. (메모리를 read, write해야되는 행위를 abstraction)
- DIP에서는 로우 레벨에 의존성을 갖는 부분을 Abstraction 함.